
Posted by Mario Baldi on February 24, 2020
Pensando Systems recently introduced a Distributed Services Card (DSC) based on a custom, fully-programmable processor optimized to execute P4 programs. The DSC is the centerpiece of a Distributed Services Platform designed to deliver high-performance, scalable networking, storage and security services. This unique approach removes the appliance bottleneck, offers unmatched visibility on traffic, and provides significant benefits for various use cases in private, public or hybrid clouds, as well as enterprise data center networks where east-west security concerns are increasingly becoming an issue. Easily installed in standard servers, the DSC, shown in the figure below, includes specialized hardware blocks to accelerate computation intensive functions, such as compression and encryption, and relies on P4 to provide dataplane programmability at wire rate.

Figure 1: Distributed Services Card.
The Power of the Network Edge
Network switches have been the initial focus of P4 programming, but the principles of P4 when applied to the endnodes at the periphery of the network can fulfill an even greater potential. Endnodes can implement network, security, and storage services in a scale-out model, similar to the one leveraged for cloud computing. Services implemented in P4 at the network edge scale naturally, because as more hosts and workloads are added to the network, more DSCs with their processing resources are also added. At the same time, more sophisticated processing can be performed on each packet, given that (i) edge devices deal with lower packet rates and (ii) the closeness of services to the traffic source and destination can provide added value in implementing application logic.
If services are implemented in a distributed fashion at the network edge, traffic naturally hits them, without the need for complex and inefficient mechanisms to steer traffic through centralized appliances. This is especially true for East-West traffic (i.e., among workloads), which in modern cloud data centers, accounts for about 90% of the overall traffic.
Cloud and enterprise data centers are typically organized around Layer 3 Clos networks with the well established spine-leaf topology. Leaf and spine switches are simple, high performance IP routers that utilize IP ECMP (Equal Cost Multi-Path) routing to spread traffic flows across multiple paths, thus achieving high throughput by leveraging all available transmission resources. In this scenario, it is impossible to have centralized appliances naturally on the path of any packet.
Instead, flows must be steered through the appliances, which results in a phenomenon called traffic tromboning: packets have to cross the Clos network multiple times, disrupting the traffic optimization offered by the ECMP routing implemented by the spine and leaf routers across the Clos network. Moreover, appliances themselves are prone to be a traffic bottleneck and single point of failure.
Cloud providers have long identified this issue and have moved all networking, storage, and security services from appliances in the core of the network to the periphery, on the server itself. Just as compute and storage systems are adopting a “scale out” approach, so too the networking and security elements of the data center must adopt a scale-out services architecture and these functions need to find a new home in this model. The ideal place to instantiate these services is the server edge (the border between the server and the network) where services such as firewall, encryption, tunneling and VPN termination can be delivered in a scalable manner. In fact, each server edge is tightly coupled to a single server and needs to be aware only of the policies related to that server and its users. This approach naturally scales – as more services capabilities come along when new servers are added.
However, a pure software-based solution does not scale at cloud level and dedicated hardware is required in the host. Because these services are complex and evolve over time, fixed function hardware is also not a viable option. Hence, P4 programmable adapters, such as the Distributed Services Card, are a perfect fit to effectively support services at the network edge.
P4 is a key enabler of the DSC flexibility, while ensuring its high-performance. Designing a processing architecture for the efficient execution of P4 programs and implementing applications on it offered Pensando a way of getting deeply involved with P4. While the language has proven a very powerful tool, some important possible extensions were identified in the process. Going forward, Pensando would like to share the matured experience and ideas with the P4 community through its active participation in relevant Working Groups with the goal of getting feedback from its very experienced members. This can have the valuable twofold outcome of Pensando incorporating support for new features proposed within the community into its products, as well as having the community embrace some of the extensions and ideas matured within Pensando and including them into relevant specs.
The Distributed Services Card (DSC)
Figure 2 shows the DSC architecture. The P4 Packet Processing Data Plane provides high performance packet processing capabilities through a set of programmable pipelines that are optimized for protocol processing: each stage includes table lookup logic, as well as specialized processors to perform header field manipulation. Outstanding performance in terms of throughput, limited latency and jitter is ensured by the high degree of parallelism offered by multiple parallel sequences of pipelined stages. Pipelined execution of a P4 program represents the best option to minimize the probability of data cache misses (since each stage operates on a single table and a specific subset of the metadata that are likely to fit into local cache) and avoid fetching instructions from outside cache (since, as a result of table matches, each stage only executes simple actions that are implemented by a small set of operations).
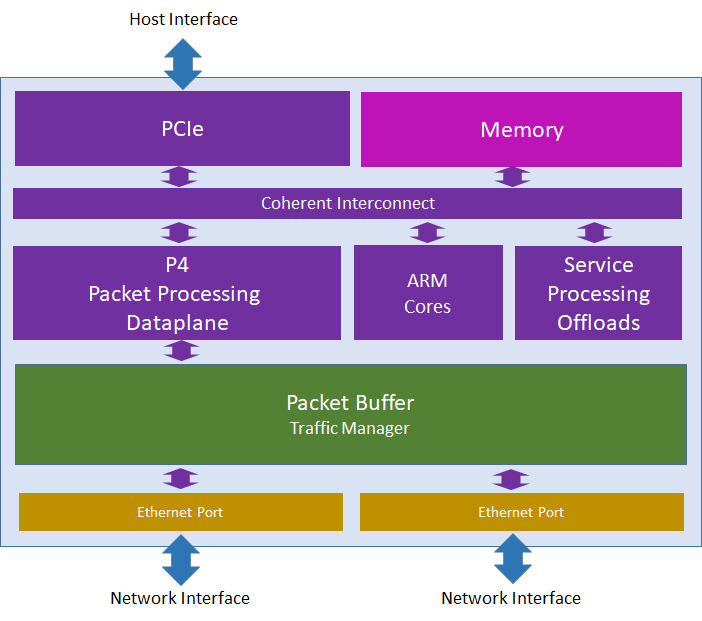
Figure 2: Distributed Services Card Architecture.
The number and organization of stages in various pipelines is key to ensure the capability of performing complex processing and versatility, respectively. If the number of stages that can be pipelined is not large enough for implementing a given functionality, packet recirculation is necessary, thus affecting achievable throughput. In the DSC, stages are organized in separate blocks of parallel pipelines. Since each pipeline has a maximum amount of packets per second it can process, the degree of parallelism in each block ensures wire rate operation capability. Different blocks can be dedicated to specific roles (such as input processing, output processing, etc.), as well as chained among themselves to create longer pipelines. Also, blocks can be chained with other processing modules (i.e., ARM Cores and Service Processing Offloads) to support more complex and efficient processing. As proven by the ability to execute various complex applications (including, but not limited to, SSL/TLS offload, NVMe-oF/TCP, stateful firewall) at wire speed, this design provides impressive scale and good granularity to alternate processing performed in a pipeline with processing performed by the other processing modules. Moreover, pipeline blocks can fetch and deliver packets from and to DSC memory, the host, and the Packet Buffer. In order to fully leverage the versatility of the specialized processors deployed in the pipeline and the tight integration with other components of the card, programming relies on an extension of the P4 language.
A Packet Buffer acts as a central on-chip packet switch that delivers packets from the network interfaces to the P4-programmable packet processing data plane and vice-versa.
The Service Processing Offloads are specialized hardware modules purposely optimized to handle specific tasks at wire speed, such as cryptographic functions and compression/decompression.
A set of ARM Cores enable more sophisticated data plane processing alongside the fast path packet processing offered by the P4 Packet Processing Data Plane. Moreover, the Linux based environment running on these processors offers computation power for control and management plane functions.
All three processing modules (P4 Packet Processing Data Plane, ARM Cores, and Service Processing Offloads) can access the card Memory through a Coherent Interconnect. The Memory can also be mapped onto the PCIe space for I/O access from host software. Since the card Memory can be accessed by all processing modules, it can be used to keep state information required for stateful processing of packets, such as, for example, TCP offload. Moreover, it can be used to store full packets when their payload needs to be processed, which is key in application layer processing.
In order to enable access to full packets when operating at wire speed on both network interfaces (i.e., at 200~Gbps), the memory bandwidth has been designed to read and store each packet at least once, in addition to performing a number of table lookups and state updates while the packet is being processed.
Configuration and management of applications that run on the DSC can be performed through either the PCIe interface (i.e., by the host) or the network interfaces (i.e., by a remote controller, such as Pensando’s Policy and Services Manager or PSM). The DSC exposes a REST and a gRPC API that can be deployed by central controllers or management systems.
Pensando is currently shipping two DSC versions: one with two 10/25 Gb/s ports and one with two 40/100 Gb/s ports, each fractionable as two ports at 10, 25, or 50 Gb/s. Although available on the market for a short time, a few customers are already deploying the cards in production environments.
While the DSC is offered as part of a Distributed Services Platform on which Pensando has developed a number of applications (including both control and data plane components), selected customers are leveraging an early version of DSC development tools to implement their own applications on the card. However, opening the platform to programming by a wider user community will require the availability of an architectural model and a full set of powerful development tools. In working towards these objectives, Pensando is committed to actively contribute to the Architecture Working Group efforts around the specification of a Portable NIC Architecture (PNA) and possibly propose within the Language Design Working Group extensions to the P4 language geared towards the interaction between NIC and host over a PCI bus. As a longer term objective, Pensando is considering to open some of the applications running on the DSC so that community members and customers can customize them by easily adding P4 code that implements their own features. In light of this, Pensando will work with the P4 community to add support for incremental programming and possibly new architecture models.
For further information on Pensando please visit https://pensando.io or send mail to info@pensando.io.
